
These notes have so far covered ways of getting data from a written source (transcripts or existing typescripts) into various forms. There is a great potential for using computers for more detailed analysis, including phonetic analysis of digitised sound (using Signalyse for example), morphological analysis (PC-Kimmo) or writing programmes for testing grammatical models. Natural language parsers are being developed in many parts of the world, there are very interesting possibilities for such software to be used in the Australian scene.
Once you are able to work with software of that kind you won't need these notes anymore.
Conc is designed for the intensive study of a text, by producing an interactive concordance: a list of all the words occurring in it, with a short section of the context preceding and following each occurrence of a word. It is similar to a key word in context (kwic) index, except that the Conc index does not have to be restricted to particular words.
Conc can also produce a more conventional index, consisting of a list of the (distinct) words in a document, each with a list of the places where it occurs. It can also do some simple statistical studies of a text, such as counting the number of occurrences of words that match a 'pattern' (a variation on Unix regular expressions).
Conc displays the original text in one window (figure 1)
Figure 1. The text window.
and the concordance of the text in another window (figure 2).
Figure 2. The concordance window

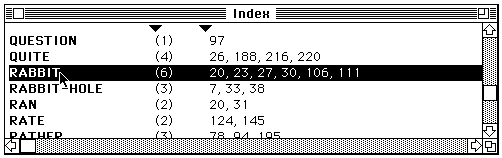
If requested, the index is displayed in a third window (figure 3).
Figure 3. The index window.
Clicking a particular word in the concordance will jump the text display to that word in the main text, thus seeing a larger context than is possible in the concordance, which is limited to one line per word. It is also possible to click in the index and locate the corresponding group of lines in the concordance (and the first occurrence in the text), or to click a word in the text and locate the corresponding position in the other windows.
Conc can produce not only a word concordance but also a morpheme or letter concordance. A letter concordance (all the letters (characters, phonemes) in a document) can be limited to just those letters that occur in a particular environment. This is useful for doing phonological analysis. Letter concordances can be done either on flat text or on interlinear text. In the case of interlinear text, the letter concordance can be restricted to selected fields.
Conc has a limited multigraph feature, currently for flat text files only. Multigraphs are allowed in search patterns and count as just one letter; for example, with the multigraph ph=f in force, a single 'match any character' will match ph.
The basic way of referring to location in the input text is by line-number, as in the above example, but this may not be convenient. As well as handling a flat text, Conc can work with a marked-up interlinear text, particularly of the format used by the IT application. The way Conc handles references is modified by a dialogue box as shown in figure 4:
Figure 4. The Text Properties dialog box
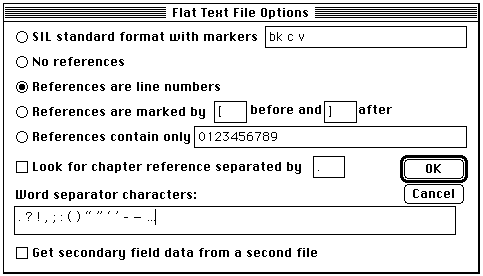
The default choice shown above is "References are line numbers." In addition,
there are several other referencing schemes available.
* No references shown in either the concordance or index.
* User-defined references (typically numbers) with option of two levels of
referencing (like section and subsection).
* SIL standard format markers.
Pros:
* runs on the smallest Macintoshes, and runs quickly once the index is built
* good documentation; not indexed but searchable by word-processor
* handles, but not limited to, field-oriented standard format files
* allows a fairly easy method of creating a concordance or index of a text
Cons:
* The text to be indexed, and the index itself, must fit in the available
memory.
* Printing the text window is not supported, and printing is limited to 128
pages per printout.
* There is no way to interrupt lengthy operations such as sorting a large file.
(However, exporting can now be interrupted.)
* Under certain low-memory conditions, Conc may exit rather ungracefully.
* Lists of words to include or exclude are limited to the 240 characters that a
simple dialog box item will hold.
* pattern matching requires familiarity with Unix-style regular expressions
* sorting will not proceed in the background (when Conc is hidden)
Current version: 1.76 beta (December, 1993)
Application size: 167k
Suggested minimum RAM: 512k
Documentation: 242k Microsoft Word file; sample texts and concordances
Author: John Thomson, SIL
Available from: ? info-mac archive, including on archie.au
Review by: David Nash
Consistent Changes and Word Format
These two programmes together allow you to change regular expressions in a document (as does Nisus, see below) and to format the document for presentation. They are designed to work with FOSF files that are marked up with backslash codes (see appendix 1 for an example).
Warning - this is a P-plate driver's review of FileMaker Pro, the microchip equivalent of having a Brock Commodore assessed by a sedate old man who drives it only around the corner to bowls on a Saturday afternoon. This program has many more capabilities than the fairly basic ones I will touch on here, and if this review arouses your interest you should explore the program in more detail. I believe it is site-licensed at many campuses, so you can try it on the network before you buy it for your personal machine.
FileMaker Pro is a database organiser. I use it for a number of purposes - annotated bibliographies retrievable by author, title, geographic region, topic etc.; class and student files; comparative work on the prefixal paradigms of non Pama-Nyungan languages - but like most linguists my major use for a database organiser is in dictionary preparation. FileMaker Pro (FMP) on its own will not perform all the data manipulation operations we require for dictionary production, nor is it sufficiently flexible to take over the final publication-quality print-out of your dictionary. It can not replace the back-slash coded text files which have become the standard format for dictionaries over the last decade. Its power, rather, comes from coupling it to such text files. Once you learn to move data between text and FMP files - a simple enough procedure, and well explained from the FMP perspective in the manual - FMP becomes a powerful, efficient and user-friendly front-end for your text file. (Note though that from the text file perspective you will have to be familiar with merge- and tab/comma- separated file manipulation strategies to really get the interface with FMP rolling properly.) I think that most linguists would even find that for most of their dictionary preparation time the FMP document would be their preferred master file, data occasionally being moved to a text file for such things as string searches and replacements (and imported back into FMP when these operations are complete), but otherwise not requiring to be downloaded to a back-slash file until a fully formatted professional print-out is needed.
FMP works like this: You name the fields you want your data organised into - e.g. language item, language gloss, English meaning, part of speech etc. You can add new fields to the file at any time, you can delete fields at any time, you can change their names. You can specify whether the field should have a unique entry; this works on an individual word basis rather than on the entry as a whole. You can set the program to refuse to accept a word which has appeared in any previous entry for that field. This is handy in the elementary stages, for example when you are compiling word-lists from different sources or unorganized field-notes, and want to avoid repetitively typing in, say, the same language item and gloss over and over again. But I find that as files get larger this facility runs too slowly for the limits of my (im)patience, and in any case its often necessary to repeat words in different entries when preparing dictionaries. You can also specify a list of values for any given field, a convenient feature for standardising your part of speech abbreviations when entering your data. And you can automate data entry for any given field; so when keyboarding items from a particular dialect or particular source linguist you can get FMP to insert automatically the relevant names into the appropriate fields.
Once you've named your fields FMP will provide you with a standard layout, and you can begin to enter data. The standard layout lists field names down the screen, and next to each provides a box in which the data appears. For each field you can enter a maximum of 64K of data; FMP will store it all, but the amount that appears on-screen (and the amount that will be printed out) is limited by the size of the data entry box. Layouts, however, are fully adjustable; you can rearrange and resize them however you wish. You can add graphics, and you can install buttons that invoke a range of FMP commands. You can have as few or as many fields in a layout as you want. And the program provides a number of built-in layout options, including columnar organisation of fields. The beauty of FMP is that for any one file you can design as many different layouts as you like (constrained only by available disk space and maximum file size (32MB)). So while you may want your dictionary ultimately to have entries in up to 20 or more fields, for initial word-list compilation you might want just to enter in language item, part of speech, gloss and comment fields. To avoid constantly scrolling through field headings that you don't want to fill in, you arrange a layout that contains just the fields you want, and order them in the way that best suits your keyboarding procedures. You can print from any of the layouts you have designed for a particular file. Useful print options include column printing as well as the compacting of fields for which no data has been entered.
This flexibility of layout is particularly useful when language workers with limited linguistic or computing background are contributing to the database. These workers can operate with a simplified and friendly layout, but the data they put in goes straight into the master file. The additional fields in these entries can be filled in later by the linguist, working with a more complex layout. And the entries of these workers can be flagged as requiring attention from the dictionary co-ordinator by having automatic date and/or source information, invisible in the layout of those workers, inserted as separate fields.
For each field you set up FMP maintains an index of all words you have entered into it. There is a Find facility which then enables you to collect all instances of particular words. There is also a reverse function, an Omit command, which enables you to omit from current consideration all records containing a particular word in a certain field. Multiple Finds and multiple omissions - or a combination of the two - are also supported. It is important to note, however, that the Find and Omit functions are sensitive only to word initial strings; that is, you can readily find whole words, and you can readily find initial portions of words. You can also find non-initial strings, but this is not as straight-forward, since you have to employ the wild-cat "zero or more characters" symbol as a dummy initial string. More important to observe here is that there is no global find-and-replace facility for particular strings. You can't for example change all instances of /dj/ to /dy/ within FMP; for a change like this export of the data to another program is required.
FMP stores records in the order in which they are entered. Records can then be sorted according to whatever field order you specify, and for ascending or descending order, as you sepcify, for each field. Sorting is by the initial string of each field. There are inbuilt international sort order options (English, Finnish, Greek etc.), but the sort order cannot be individually customised. In addition there appears to be no facility for saving a file in a particular sort order. Instead you have to download your sorted file into a cloned version of your current file, an easy enough process, and adequately described in the manual, but something of a nuisance at times.
Current version FileMaker Pro 2.0v4
Application size 1MB
Suggested min RAM 1200K
Documentation Detailed user's guide, tutorials, sample files, on-screen help
Author Claris Corporation
Available from any Mac outlet; also site-licensed at a number of campuses
Price $220 staff/student price for Education version
Review by Ian Green
This free software is the latest version in a line of concordancing and indexing software that includes Texas.
It is a HyperCard stack which indexes text files and provides extremely fast access to keywords. It supports boolean searches (and, or, not) and provides context at the level of the line of the target, or a chunk of text either side of the target. Files of any length can be indexed (tested on files of over 20 Mb in length) and retrieval speed is not noticeably affected by the size of the file.
It does not use a 'stoplist' (words not included in the index). All words are included in its index of a file. Indexing can take a while, and indexes can take up to 150% of the size of a small file, but become smaller the larger the file to be indexed.
Pros:
* provides extremely fast access to data no matter how large the file.
* easy to use
Cons:
* lists only exist as temporary fields in the document and are not true
concordances.
Current version: 1.03, March 1990
Application size: 120 k
Suggested minimum RAM:
Documentation: 246 HyperCard stack, 42Kb text file
Author: Mark Zimmerman
Available from: ? info-mac archive, including on archie.au
Review by: Nick Thieberger
HyperCard is a mixture of database and presentation software. It can be very useful for linking graphics to sound and text. The Katherine Regional Aboriginal Language Centre has produced very good examples of HyperCard material for teaching Australian languages, and AIATSIS has produced a set of material illustrating Australian languages for secondary school students.
IT (Interlinear Text processor)
IT takes a text file as input and allows you to supply meanings to the individual words. It presents the English meanings in line underneath their language equivalents. The file created by this process is a text file which can be read by any other word-processor.
The wordlist created by IT can be exported as a marked-up text file to be the basis for a dictionary.
To use IT (on a Macintosh) , first create a text file (for example a transcript of a tape) and then select 'New' from the IT menu. IT prompts you through the next few steps to create a new document. You will be prompted to create a text model, a wordlist file (called a lexical database) and a text preparation file. There are samples of these provided which you can use to see how IT presents its information. You can use these existing models, or you can create your own.
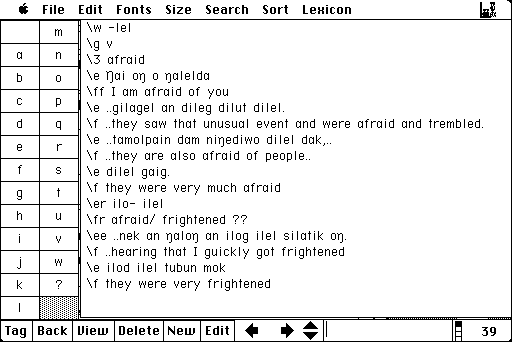
This is what a typical glossed sentence looks like:
\tx Warrarn-ja -yarna -jananya wimi ju -npa -yarna ngurra -ngka
\mr Warrarn-ja -yarna -jananya wimi ju -npa -yarna ngurra -ngka
\mg country-Loc-1plexS-3plO story vbl -pres-1plexS camp,home-LOC
IT allows you to have up to 14 lines below the text line, allowing you to put in information about idiomatic usage, or sources, or dialects, as well as the meaning (or gloss). You can then supply free text glosses which are linked to the level of the unit (sentence, paragraph or whatever you choose).
The output of IT can be used by Conc to produce concordances on particular lines of interlinear text.
Pros:
* documentation is good. The HyperCard version of the manual uses hypertext
links to cross-reference information.
Cons:
* the lexical database has to be exported to a text file to be edited, and
imported back into IT to be used again.
* setting up a file can be complicated.
Current version: 1.01r7 (Dos version is 1.2)
Application size: 282 kb (+ 1,336 k documentation in HyperCard)
Suggested minimum RAM: 362
Documentation: Printed manual costs US$200, but software and HyperCard stack
version of manual is free (available from the internet site sil.org).
Author: Gary F. Simons and John V. Thomson, Summer Institute of Linguistics
Available from: Linguist's Software, P.O. Box 580, Edmonds, WA 98020-0580, USA,
tel. (206) 775-1130, fax (206) 771-5911. Internet ftp site <sil.org>
Review by: Nick Thieberger
MacLex is a shareware application designed for 'Lexicon Management & Reversal'. The author is a linguist who has himself maintained dictionaries in his work in Arnhem Land and PNG.
MacLex lets the user navigate through the vocabulary's records in a variety of ways, a bit like with HyperCard. The data files can be edited through MacLex, and like HyperCard any changes are immediately saved to disk. However the data files are just plain text, structured into labelled fields, i.e. vocabulary files in SIL-style format, and so can also be handled with any other editor. Version 3 has an extra module called Naturalistic Inquiry data manipulation, described in two additional chapters of the documentation. It is an experimental additional which promises to integrate textual analysis with the lexical database.
This is a sample screen showing how a plain text file is presented; the alphabetical divisions shown by the square buttons on the left are created automatically:
Provison is made in the MacLex editor for serching the lexicon by specific fields (headword, meaning, example sentence and so on), and for changing strings within specific fields only.
MacLex can also sort the lexicon on any field. Apart from use in sorting on the head word field, or sorting the reversed finder list, the manual shows how to sort by semantic field, and the package comes with a file of suggested semantic category codes ('Lowe & Nida').
This is one of the powerful configuration screens, the one in charge of creating a finder list:
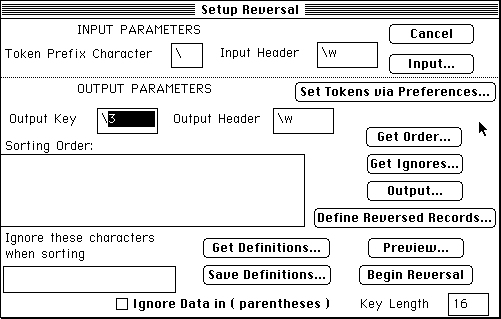
Pros:
* runs on the smallest Macintoshes, and runs quickly
* good documentation; not indexed but searchable by word-processor
* specialised for field-oriented standard format files
* a convenient way to display on a Macintosh screen vocabulary that is
basically in field-oriented format
* a quick and easy way to sort a lexicon that is possibly spread over many
files, in a custom sort order, or any field
* allows a fairly easy method of creating a 'reversal' (usually, an English
finder), including for a lexicon with separated senses and subentries
Cons:
* the application is still under development; some error conditions are treated
unceremoniously
* parts of the interface are unusual for someone used to basic Macintosh
applications
* finder list entries are limited to a single indexing word from each gloss; so
'cold southerly wind' can be indexed as 'cold' or 'southerly' or 'wind' but
only one of these (without an ad hoc 'workaround')
* demanding on RAM unless the lexicon is split into files of less than 32k,
which would normally therefore be quite numerous
Current version: 3.0 (26 Feb 1994)
Application size: 245k, plus about 11k of settings files
Suggested RAM: 560k; minimum 384k
Documentation: 447k folder of 9 Microsoft Word files; sample lexicon
Author: Bruce Waters, SIL-PNG.
Available from: directory software/mac at sil.org (198.213.4.1) by ftp;
info-mac archive, including on archie.au (possibly earlier version)
Reviewed by: David Nash
Nisus is a word-processor which incorporates some features of page layout programmes (including graphics and page imposition). Of special use to the language worker is its 'GREP' regular expression parser. A 'regular expression' has a constant form but can have different content. For example, we know that sentences that we type on a word processor end with a carriage return. We can represent the sentence as being everything that comes between two carriage returns, in the regular expression code of Nisus or Qued/M it would look like this:
\r.:+\r
If we wanted to note that a sentence could also come at the beginning of the document, then we could broaden the expression to this: \(:s|\r\).:+\r, which provides for either a return, or the document start to occur as the first character of the document.
We know that words have spaces before and after them, in the regular expression code of Nisus or Qued/M it could look like this: \s[^\s].:+\s (which means a space followed by any number of characters that are not a space followed by a space.)
Using this regular expression code we are able to manipulate text material for various types of output. It is possible to have a master file which is never printed out, but parts of it are produced for different audiences: local people; children; tourists; academics.
Using the regular expression (GREP) Find/Replace function in Nisus.
Part one
Finding all headwords and semantic field markers and swapping their position so that the sorted list will be by semantic field rather than by headword. A semantic field marker is one which says that the word belongs to one group, or semantic field like body parts, or bird names, or plant names and so on. The file we are working on has the following structure:
\w headword
\p part of speech
\d definition
\s semantic field
First, select Find/Replace in the Tools menu. Next, make sure that the type of search you are doing is a PowerSearch+, not a Normal Search. While you are looking at this window, you can also click at the top right corner to see a selection of prompt menus for regular expression (GREP) searches). To find the parts that we are interested in we need to search first for \w followed by other characters up to, but not including the next backslash (\), this will find the headword field only and the expression we need to write is as follows:
\\w.:+\r
Note that the backslash must be written twice since Nisus uses it in its own GREP searching language. Searching for \\w will find \w in the text.
The next step is to find everything between the headword and the semantic field information. If we include the first expression in parentheses (brackets) it will help us divide what we are looking for into chunks (note that we use a backslash before each parenthesis to conform to the GREP language):
\(\\w.:+\r\)\(:.:+\)\(\\s.:+\r\)
When typing into the search window, be sure that the text that you are typing is set to any size, any font, and any style by selecting the text and then checking the appropriate entries in the Font, Size and Style menus, unless you actually do want to find a particular size, font or style.
Now that we have found all of the parts of the entry we were searching for, we can change their places. To do this, simply count the number of items in parentheses in your search. Each of them is given a number, and so to swap the third one with the first one, which is what we want to do, you just need to put this into the Replace box:
\3\r\2\1
If you now click Replace All you will change the structure of all of your entries which conform to the structure you specified in the search.
If you now take out all carriage returns in the file (by searching for all \r and replacing with nothing), you can insert a carriage return only before \s (by looking for \\s and replacing with \r\\s) and then, by selecting sort [[paragraph]] from the Edit menu, you will have all the file sorted by semantic field.
Part two
Once you know your way around Find/Replace and GREP, you can set up macros, which are like recordings of a set of search and replace functions. Macros are especially useful if you often do the same type of changes to files. So, for example, you could have a macro to reverse your entries and definitions in a dictionary, or to strip particular words or parts of words from texts. Nisus comes with some macros which you can look at for ideas to copy and model your own macros on.
The following macro (b) takes a sequence of the form (a) and produces the output (c)
a) \d hill, mountain <tab> \w headword <tab> anything else <carriage return>
b) find/replace "\\d\( .:+\)\(, |;\)\*\([^\s]:+\) \(.:*\)\t\(\\w.:+\)\t\(.:+\)\r" "\\d\1\2\3\4\t\5\t\6\r\\d \3\4\2\1\t\5\t\6\r" "ATtg-w-O"
c) \d mountain, hill <tab> \w headword <tab> <anything else> <carriage return> '
The following macro (e) takes a sequence of the form (d) and produces the output (f):
d) \d yellow nailtailed *wallaby <tab> \w headword <tab> <anything else> <carriage return>
e) find/replace "\\d\(.:+\)\*\(.:+\)\(\t\s.:*\)\(\)\(.:+\)\r" "\\d\1\2\3\4\5\r\\d \2\:\1\2\3\4\5\r" "ATtg-w-O"
f) \d yellow nailtailed wallaby <tab> \w headword <tab> <anything else> <carriage return>
\d wallaby: yellow nailtailed wallaby <tab> \w headword <tab>
<anything else> <carriage return>
Current version: 3.47
Application size: ~2,000k including dictionaries and macro samples.
Suggested minimum RAM: 1024k
Documentation: Manual and online help
Author: Paragon concepts
Available from: Commercially available
Review by: Nick Thieberger
Qued/M is a text processor that includes the GREP function of Nisus, but is much faster since it does not have any of the formatting features of Nisus. If you want to use both Qued/M and Nisus, you should do all of the structural changes with Qued/M followed by formatting changes in Nisus.
Shoebox is a Dos programme which links a FOSF coded dictionary to a text glossing facility. It treats each of these as a database, and up to seven databases can be used at one time. There is no required structure for the databases, so that various kinds of data can be included in each. The potential of this type of access to data is that you can have fieldnotes in one database, texts, a dictionary, bibliography and so on in others.
TACT (Text Analysis Computing Tools)
TACT is a set of very powerful concordancing and text manipulation software designed for use in comparison of editions, as well as in statistical analyses of texts. It includes text-tagging software and a collocation concordance progamme. It is Dos-based only.
Current version: 2.1ß, Jan 1994
Application size: ~2,500k
Suggested minimum RAM:
Documentation: Manual costs, software is free
Author: Ian Lancashire et al, University of Toronto
Available from: ftp.epas.utoronto.ca in /pub/cch/tact/ (subject to change)